
A versennyel még nem sikerült haladnom, így arról még kevés újdonsággal tudnék szolgálni, viszont van egy téma, amit eddig elkerültünk, de érdemes vele foglalkozni. Ez pedig a modellek témája. Eddig átléptem a problémát azzal, hogy ha megvan az adat és a célváltozó, építünk rá egy modellt; most nézzünk a mélyére: milyen modellekkel dolgozunk leggyakrabban?
Személy szerint amióta adatbányászom, két modell-típussal volt főként dolgom: döntési fákkal és regresszióval. Ennek több oka is van: ezek régen bevált, egyszerűen magyarázható eljárások, azaz a modell eredménye könnyen átadható az üzlet részére. Megfigyelésem szerint a tanácsadó szektor (amiben én is tevékenykedem) legnagyobbrészt ilyen modellekkel dolgozik. Saját vagy ennél bonyolultabb algoritmusokat újszerű problémákra vagy specifikus területen alkalmaznak, és vagy a cég saját adatbányászai programozzák le, vagy az egyetemi szférából kerül ki a fejlesztő.
De nézzük is a két fent említett modellt:
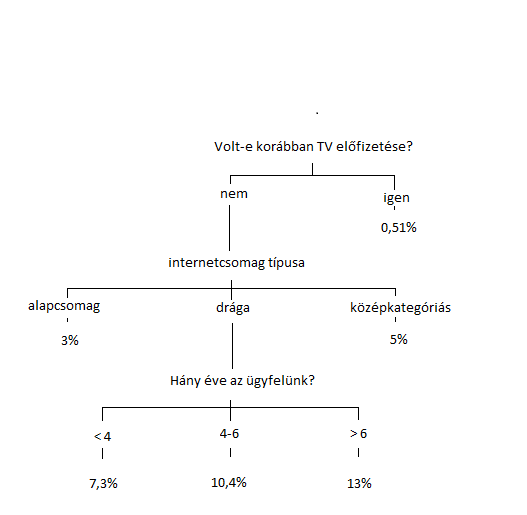
A döntési fa a legegyszerűbb és ennek ellenére nagyon hatékony modelltípus. A lényege, hogy az adatbázist darabolni kezdi az egyes lépésekben egy-egy változó értékeitől függően. Olyan mutatók mentén, mint pl. az entrópia (információ-nyereség), kiválasztja, hogy melyik változó különböző értékei mellett lehet úgy darabolni az adatbázist, hogy a részekben a legnagyobb legyen a különbség az esemény-arányok között. Egy egyszerű példa a döntési fára: az alábbi fa egy hipotetikus modellje annak a döntésnek, hogy ki fog venni legvalószínűbben új TV csomagot. Összesen három változó felhasználásával az ügyfeleket 6 részre osztja, és minden csoportban (levelek) megmondja, hogy mennyi a vásárlók aránya. Ez nagyon szemléletes és viszonylag egyszerű modell, két dologra is alkalmas: Egyrészt az ügyfeleket sorrendezni lehet az alapján, hogy melyik csoportba kerülnek, és azoknak ajánlani a TVcsomagot, akik valószínűbben megveszik, másrészt a változók megvizsgálása után levonható arra vonatkozóan következtetés, hogy hogyan érdemes változtatni az üzletmeneten. Ebből a fiktív példából kiindulva például dönthetünk úgy, hogy felülvizsgáljuk a terméket, mivel akinek egyszer már volt ilyen, azok elhanyagolhatóan kis arányban vesznek újra, tehát valószínűleg nagyon elégedetlenek.
A regressziós modell ennyire nem szemléletes, minden egyes bemeneti változóra megmondja, hogy értéke milyen mértékű változást okoz a célváltozó értékében. Nézzünk egy másik példát, mondjuk, hogy egy lakás árát jósoljuk meg a jellemzői alapján. Egy regressziós modell minden egyes numerikus változóhoz képez egy szorzót, majd az egyes szorzatokat összeadva kijön az lakás jósolt értéke, pl:
ár = hány négyzetméter a lakás * x1 + lakás állapota (0-100-as skálán) * x2
Az ár kiszámításán kívül a modellből látszik, hogy az egyes tényezők hogyan befolyásolják a végső árat: ha egy együttható negatív, akkor a jellemző növekedése csökkenti az árat, ha 0-hoz nagyon közeli, akkor annak kis változása kevéssé befolyásolja azt.
Ezek a modellek hát azok, amiket leggyakrabban használunk, minden komolyabb adatbányászati szoftverben ezen modelleknek több fajtája is megtalálható beépítve.
Ajánlott bejegyzések:
A bejegyzés trackback címe:
Kommentek:
A hozzászólások a vonatkozó jogszabályok értelmében felhasználói tartalomnak minősülnek, értük a szolgáltatás technikai üzemeltetője semmilyen felelősséget nem vállal, azokat nem ellenőrzi. Kifogás esetén forduljon a blog szerkesztőjéhez. Részletek a Felhasználási feltételekben és az adatvédelmi tájékoztatóban.