Lassan - két nap múlva - egy éves lesz a blog, ami nem sok idő, de pár gondolat összegyűlt ezzel kapcsolatban bennem. Például, hogy a kezdőötletet a blog elindításához a Numerátorok c. könyv olvasása adta, ami egy újságíró szemszögéből mutatja be az adatbányászok világát, érdekes alkalmazási területekről ír olyan megfogalmazással, hogy az adatok világában teljesen járatlanok is megértsék. Ez inspirált arra, hogy blog formájában ismeretterjesztő jelleggel írjak általánosságban az adatbányászatról illetve a saját tapasztalataimról.
Sok visszajelzést kaptam az utóbbi hónapban a bloghoz, ezt mindenkinek köszönöm ezen a fórumon is. Azt írtátok, szívesen olvasnátok a felszín mélyére menő, konkrétumokat is tartalmazó posztokat, ezt a jövőben igyekszem teljesíteni. Ezen felbuzdulva egy-két hét múlva - amint visszajövök nászútról - jön egy poszt az iskolapéldák és a való világ eltéréseiről.
A legnagyobb visszajelzés számomra hogy a blog “falain” kívülre is eljutni látszik az ismeretterjesztő tevékenységem, ugyanis meghívást kaptam a szeptemberi NLP meetupra, ahol adatbányászatról adok elő. Akit érdekel, a meetup oldalán egy rövid összefoglaló van már fönn az előadás témájáról.
Köszönet a lelkes olvasóközönségemnek, hogy mindig motivációt ad a következő bejegyzés megírásához, például egy "like"-kal :)
Idén augusztus utolsó napjaiban Budapesten került megrendezésre a RapidMiner Community éves konferenciája. A négynapos konferencia két napján oktatás és vizsga volt, míg a másik két nap előadásokból állt, ezt egy vacsora egészítette ki az A38 hajón és egy romkocsma-látogatás volt a csütörtök esti program.
A konferencia résztvevői főként Kelet-, Közép- és Dél-Európai régióból kerültek ki: a magyar résztvevőkön kívül több szerb, cseh, szlovák illetve horvát előadó és résztvevő is volt, ezen kívül még Németországból érkeztek többen.
A konferencia az előadásokat tekintve is sokszínű volt: hallhattunk az új és régi RM kiegészítőkről, voltak ipari projektekről beszámolók, a Telenor is előadott a RapidAnalytics bevezetéséről.
Csak címszavakban az érdekesebb alkalmazási és fejlesztési területekről:
Tőzsdei portfólió-optimalizálás; Életstílus-elemzés és ajánlórendszerek; Számításigényes feladatok grafikus kártyán való implementálása és párhuzamosítása; Adatstream-ek bányászata; Automatikus szótárkészítés vélemény-bányászathoz; R diagramok megjelenítése; Képbányászat; Octave kiegészítő...
A leghatásosabb előadó az új RapidMiner témájú könyv írója volt szerintem, aki azzal a céllal írta könyvét, hogy bárki, aki szeretne adatbányászkodni, a könyv segítségével könnyen megtehesse. Az előadó kiemelte a könyv utolsó fejezetét, ami az adatbányászati etikát taglalja Ezért is választotta a RapidMiner szoftvert, mert ingyenes, egyszerűen tanulható és sok művelet elvégezhető vele. A könyv címe: Data Mining for the Masses, az előadás végén CD formátumban minden résztvevő megkapta a könyvet. (Ha elolvastam, véleményt is írok róla)
A konferencián beszámoltak a Rapid-I legújabb fejlesztéseiről is, amik közül az alábbiakat emelném ki:
- Kiegészítik a sokszor hiányos operátor leírásokat a Help view-ban, amit két vaskos kötetben nyomtatásban is elérhetővé tesznek
- A makrók értékei nyomon követhetőek lesznek futtatás közben (Macro view)
- Mobil applikációt fejlesztenek a RapidAnalytics felületéhez
- A kiegészítőket egyszerűen fel lehet tölteni a Marketplace-ra, ami egyelőre (de már csak néhány hétig) béta-ként üzemel, de már elég sok kiegészítő érhető el róla.
A két fél napos oktatás anyagát nagyon jól állították össze, érthető, összeszedett és hasznos is a kezdő RM felhasználóknak. Ebből ugyan nem lehet megtanulni a RapidMinert, és a vizsgához is kevés önmagában, mégis hasznos azoknak is, akik már elkezdtek foglalkozni a RapidMinerrel, de még nem rutinos használói. A vizsga nem volt kimondottan egyszerű, de gyakorló adatbányászként nem is volt nagyon nehéz, érteni kellett alapvető adatbányászati algoritmusokhoz, és a RapidMiner funkcióit is jó volt ismerni (bár ez utóbbiban segített, hogy a lehetőség volt használni a szoftvert vizsga közben). Mindenesetre pár hónap RapidMiner használattal, az RM kézikönyv elolvasásával és az oktatási anyag segítségével sikerült megszereznem a Rapid-I Analyst oklevelet a vizsgán.
Láttam és szerveztem már sok rendezvényt, így meg kell jegyeznem a végére, hogy nagyon színvonalasra sikerült szervezés-ügyileg a konferencia, köszönjük! A következő évben Porto (Portugália) városa ad helyet az RCOMM-nak.
Nem-tipikus adatok
Címkék: hálózatkutatás szövegbányászat hangbányászat web-elemzés
2012.08.17. 11:02
Az előző poszt egy nem-tipikus adatbányászati feladatról szólt, ezt folytatva arról fog szólni ez a poszt, hogy milyen nem tipikus adatok vannak még, és mit lehet kezdeni ezekkel. (Tipikus adaton a táblázatos formában/adatbázisban tárolt adatokat értem.)
Hangbányászat, szövegbányászat:
Július elején a Clementine Consulting bemutatta az IBM Modeler 15-ös verzióját, és a bemutatón szó volt a hálózat, hang- és szövegbányászatról is. Hangbányászatra az egyik működő megoldásuk, hogy egy call-centerbe befutó hívásokat egy éjszaka alatt szöveggé, majd a szöveget strukturált adattá alakítják, amin már tipikus adatbányászati algoritmusokat lehet futtatni. A beszélgetés tartalmán kívül a hangból hangulatot tudnak és szoktak még meghatározni, ennyiben mindenképpen pluszt szolgáltat a hangbányászat a bevitt szöveghez képest. Mit jelent ez a gyakorlatban? Betelefonálsz egyik nap az ügyfélszolgálatra, ami másnapra egy sornyi adatot generál a szolgáltató adatbázisába: Mi miatt tettél panaszt, milyen hangulatú volt a beszélgetés, stb. A legfontosabb, hogy mindezt emberi beavatkozás nélkül teszi, először szöveggé alakítva a hangot, majd a szöveges adatot feldolgozva, és hangulatot rendelve a szöveghez.
Hálózatelemzés:
A hangon és szövegen kívül ma a hálózatok bányászata az egyik érdekes alkalmazási terület. A telkó és bank kapcsán már volt szó hálózatokról ebben a blogban, de más területeken is érdekes hálózatokat lehet építeni. A cégek hálózata mondjuk jó példa ilyen szempontból, ahol a közös tulajdonossal, vagy címmel rendelkező cégek vannak összeköttetésben egymással. Egy ilyen hálózatot például az adóhatóság tudja jól felhasználni, és a banki tartozások szempontjából is érdekes, hiszen ha az egymással pénzügyi/tulajdonosi kapcsolatban lévő cégek közül egy fizetésképtelenné válik, láncreakciót válthat ki a hálózatban. De nem feltétlenül emiatt alkalmazzák sok helyen a hálózati elemző szoftvereket, hanem mert speciális alkalmazásokkal lehetőség van megjeleníteni a gráfot, és ez már önmagában is “jó játék”.
A hálózatban két alapvető feladattípust különíthetünk el, az egyik valami miatt érdekes csomópontok keresése. Érdekes például az a csomópont, amihez túl kevés másik pont csatlakozik (outlier) vagy éppen ‘túl’ sok. A sok kapcsolattal rendelkező előfizetőket próbálják például megfogni a bankok, telco cégek egy új szolgáltatással, mert tőle kiindulva fog leginkább elterjedni (véleményvezér). (Ez elnagyolt megfogalmazás, akit bővebben érdekel a téma, javaslom a Behálózva c. könyvet. A másik feladattípus a hálózatban egy bizonyos esemény terjedésének vizsgálata lehet, például a céges hálózatban a bedőlés terjedése.
Web-elemzés:
A weboldalak elemzését is az adatbányászati feladatok között szokták említeni, és több jellemző web-elemzési feladatot is számontartunk. Egyik ezek közül az internetes tartalmakban való keresés és automatikus rendszerezés, a másik egy-egy internetes oldal log-adatainak bányászata. Előbbit mesteri szinten űzi a google, ez érdemel egy teljes posztot a későbbiekben, míg utóbbi egy konkrét weboldal látogatottságának vagy akár használhatóságának növelése érdekében érdemes elvégezni. Az online adatok bányászatáról már volt is szó a híroldalak elemzésénél, ezen kívül rengeteg web-analitikai eszköz áll már rendelkezésre saját weboldalunk elemzésére, amit érdemes használni.
A napokban volt szerencsém (számomra) nem tipikus adatokhoz hozzájutni és szó szerint játszani vele. Végre egy igazán belemerülős, határaimat feszegetős probléma került a kezembe, így öröm volt a munka. Ennek kapcsán gondolkodtam el rajta, hogy nem véletlen, hogy mostanában sokan emlegetik a hagyományos adatbányászat halálát, és egyre inkább terjed a hálózat, szöveg-, hangbányászat. Nem véletlen, mert sokkal érdekesebb, látványosabb és ugyanezért eladható is, hiszen a vezetők is szeretnek játszani.
Visszatérve a kezdő felütéshez, amihez most hozzájutottam adat, az egy 3D pontfelhő volt, azaz xyz koordinátákat, és némi egyéb információt kaptam egy nagyobb objektum felszínének pontjairól. Így, hogy hasonló adatbázishoz még nem volt szerencsém, keresnem kellett egy adatbányászati eszközt az általam ismertek közül, amivel egyáltalán meg lehet jeleníteni a 3D képet valahogyan. Általában a lassúsága miatt nem szeretem a Rapid Minert nagy adatbázisokkal használni, de most mégis adtam neki egy esélyt, és most nem csalódtam benne.
10%-os véletlen mintát véve az adatbázisból, és bizonyos részletet kivágva a létrejött 3D képet még forgatni, színezni is tudtam a megjelenítőjében, és mivel adatot is lehet vele transzformálni, így egyszerűen át tudtam forgatni a kapott objektumokat a normál koordinátarendszerbe. Azért kellett kifejezetten adatbányászati szoftvert keresni a megjelenítéshez, mert következő jó játék klaszterezők kipróbálása volt, amihez szintén kevés szerencsém volt még a gyakorlatban. Általában nem megfogható dolgokat kell klaszterezni, mint például ügyfeleket, ahol nehéz eldönteni, hogy a klaszterezés jó vagy sem. Itt ez másképp volt, a klaszterezés eredménye jól megjeleníthető, és eldönthető, hogy tényleg egy objektumhoz tartozik-e. Több objektumom is volt a pontfelhőben, a megjelenítőn szépen el is különültek ezek, szabad szemmel szépen szét lehetett választani az objektumokat. A klaszterezés ennek ellenére nem bizonyult túl jó megoldásnak, akárhány modellt próbáltam is ki. Azok a modellek boldogultak valahogy, amik paraméterként várják, hogy hány objektumot kell megtalálniuk, de ez, amennyiben automatikusan akarunk objektumokat elkülöníteni a térben, nem igazán jó megoldás. A klaszterezés alapú megoldás tehát nem biztos, hogy jó ebben az esetben, valószínűleg más megközelítés kell majd hozzá a képfeldolgozás világából.
Az adatokat egyelőre próbaként kaptuk, de remélem lesz folytatás, mert élmény volt ilyen adatokkal dolgozni.
Javában tart már a foci EB, így a DataSolutions által megvalósított és az index.hu-n megjelent tippjátékban már pontgyűjtés okán nem érdemes regisztrálni, néhány érdekesség miatt azonban még érdemes lehet meglátogatni az oldalt. A tipp.sportgeza.hu honlapon megtalálható EB tippelős játék ugyanis nagyban eltér a többi hasonló tippelő alkalmazástól. Az idei EB-re is több cég készült játékkal, kik a közösség aktívabbá tétele miatt, kik emailcím-gyűjtő kampányként. De miért készít egy adatbányászati cég - aki sem email címeket nem gyűjt, sem közösséget nem szervez - tippelős alkalmazást? Hogy megmutassa, milyen érdekes információkat lehet kihozni ebből is. A honlap regisztráció nélkül is elérhető “Érdekességek” menüje alatt ugyanis mindenféle manapság szívesen alkalmazott ún. dashbordot fedezhetünk fel, amin a szokásos futball-meccs elemzés helyett a tippjáték alakulását követhetjük nyomon. Ha regisztrált játékosok vagyunk, olyan érdekességeket is megnézhetünk, hogy milyen a tippek eloszlása a játékosok között, hogyan alakul saját, illetve csapatunk helyezése az időben. A közösség-szervezés sem maradt ki a játékból, felvehetünk “haverokat”, akikkel ugyan nem vagyunk egy csapatban, mégis össze szeretnénk mérni magunkat velük, és ezen belül is versenghetünk.
Nem lennénk igazi elemző cég, ha nem állítottunk volna csatarendbe mesterséges játékosokat, akik kitartóan bizonyos stratégiák szerint játszanak, hogy kiderítsük, van-e olyan módszer, aminek alkalmazásával az átlag-tippelőnél jobb eredményt lehet elérni. Az öt “ágens” közül négy átlagon felüli eredményt ért el eddigi tippelései során, a csoportkörök befejezése előtt. Az ötödik ágens kilóg a sorból, de ez nem nagy csoda: ő az, aki meglepetés-eredményt vár minden meccsre, azaz mindíg a papíron gyengébb csapatra tesz,ezért is teljesít átlagon alul. Az öt ágens továbbra is versenyben marad, kíváncsian várjuk, van-e olyan egyszerű stratégia, ami a játék folyamán végig nyerő marad. Ha megtetszett a játék, még van lehetőség csatlakozni és kitalálni valami nyerő módszert, hátha még kijutsz vele az olimpiára :). Ha nem sikerül, a következő tippjátéknál reméljük szintén a játékosok között tudhatunk. Addig is kommentekben várjuk, milyen elemzéssel egészíthetnék még ki az oldalt.
Hogyan tudja az adatbányászat segíteni egy-egy állam működését? Hasonlóan egy nagyvállalathoz, az állam is rengeteg adattal rendelkezik, sok döntést hoz, amit az adatok feldolgozásával lehet támogatni. A közelmúltban több cikk is megjelent arról, mire is használják a közigazgatásban az adatbányászatot, a SAS blogjában nemrég a mikroszimulációkról olvashattunk, ami abban segíti az közszféra döntéshozóit, hogy különböző gazdasági intézkedések várható hatását akár dinamikusan (azaz az érintettek reakcióit figyelembe véve) is képesek előrejelezni. Így például meg tudják mondani, mennyi bevétel várható egy-egy adó kivetéséből. Erre kis hazánkban is nagy szükség lenne, ha a döntéshozók szánnának ilyesmire időt, talán nem kellene havonta változtatni az adók formáján és rendszerén csak azért, mert nem váltották be a hozzájuk fűzött reményeket.
(A blogból egyébként kiderül, hogy a svéd parlamentnek létezik Elemzési Osztálya. Wow)
Saját adatok felhasználásán kívül a napjainkban oly népszerű “social media” adatainak elemzésével is tud mit kezdeni a közszféra. A Bitport cikke szerint az ENSZ - szintén a SAS segítségével - arra volt kíváncsi, hogyan egészíthető ki a hivatalos statisztika a közösségi média adataival. Ír és amerikai blogok és fórumok bejegyzéseit vizsgálták a projekt keretében, és találtak olyan elemeket (pl. munkával kapcsolatos bizonytalan érzelmű bejegyzések megszaporodása), amik előrejelzik a munkanélküliséget, hosszabb távú cél pedig, hogy a munkanélküliségi politikák fejlesztésére használnák fel.
A magyar közigazgatást tekintve nem sok adatbányászati jellegű projektről adnak hírt. Az egészségügyben már évek óta emlegetik a digitalizálás komoly szintre emelését, ebből várhatóak később elemzések, illetve az oktatásban láthatunk kezdeményezést. A TÁMOP részeként projektet indítottak az oktatáskutatásban létrejött adatbázisok feltérképezésére és megosztására, ennek eredménye a http://adattar.ofi.hu/?elemzes oldalon látható. A felhasználóknak itt lehetőségük van két oktatással kapcsolatos adatbázis online elemzésére, letöltésére, és másodelemzések közlésére, ezzel próbálják segíteni az oktatók munkáját. A kezdeményezés nagyon jó irányba mutat, mert legalább felhasználják, sőt megosztják a kutatások során keletkező adatokat.
Ha ismertek ilyen kezdeményezést, projektet a közszférában, osszátok meg velünk :)
Kis szünet után újra az adatbányászati szakmáról: Miket érdemes tanulni, elsajátítani, ha jó adatbányász szeretnél lenni?
Ha az előrejelzéseknek hinni lehet, egyre nagyobb szükség lesz olyan szakemberekre, akik képesek folyamatokat átlátni, elemezni és irányítani. A computerword egy év eleji cikke szerint a jövő tech munkahelyei közzé tartozik az adatbányászati terület is, egyre több erre specializált szakemberre lesz szükség, főleg nagy és nem-strukturált adatok kezelésére. Személy szerint azt hiszem, érdemes minél több szoftvert megismerni már az egyetem alatt (adatbázis-kezelő és elemző programokat egyaránt, ez utóbbin belül fizetős és open source verziót is), mert egyre inkább nem lehet tudni, melyik ismeretére lesz szükség, hiszen ha hihetünk a Gartner elemzéseinek, egyre több szoftver tör be erre a piacra.
Pár évvel ezelőtt még nem nagyon volt olyan képzés sem, amelyről kikerülve papírt lehetett arról kapni, hogy képzett adatbányász, elemző vagy. Ez mára szintén átalakulni látszik, a szoftvergyártók többségénél létezik valamilyen oktatási csomag és vizsga is, de már nem csak szoftverhez kötött papírt lehet erről szerezni. Az INFORMS egyesületnél most tervezési fázisban van egy elemzői képesítés kialakítása, de itthon is van már kezdeményezés egy adatbányászati képzés (Adatbányászati Akadémia) indítására.
Ma már az adatbányászat alatt is minden cég mást ért, érdemes ezen a területen belül is specializálódni: a jelenlegi irányok szerint nem árt megismerkedni a BigData és a hálózati szoftverekkel az adatbányászati alapok mellett, mert az adatmennyiség és bonyolultság is növekedni látszik. A jelenlegi álláshirdetések között egyre több specialistát keresnek, akik már az algoritmusok tervezésétől kezdve végigviszik az elemzési folyamatot.
Mindebből látszik, hogy nincs egyszerű dolga annak, aki adatbányászattal szeretne foglalkozni, célszerű egy specifikus területet találnia, amiben tud érvényesülni, de még így folyamatosan képeznie kell magát, hogy a szakmán belüli változásokkal lépést tudjon tartani.
… akarom mondani adatbányász?
Az adatbányászat annyira szerteágazó terület, hogy érdemes szerintem egy posztot szentelni annak, hogy kiből is lesz jó adatbányász, milyen érdeklődési kör kell hozzá, hol kínálnak egyáltalán ilyen ismereteket? Ez a poszt még jól jöhet azoknak is, akik idén választanak felsőoktatási intézményt.
Előszöris azon gondolkodtam el, a szakmabeliek között kinek milyen végzettsége van, és miben különbözik a nézőpontja. Nem soroltam fel minden végzettséget, csak a szerintem legkülönbözőbb jellemző nézőponttal rendelkező szakokat.
A matematikus, statisztikus: programtervező vagy elméleti matematikusok illetve statisztikát hallgatók számára egy lehetőség, hogy adatbányásznak állnak. Ők könnyen értelmezik a grafikonokat, függvényeket, így az adatelőkészítés fázisban verhetetlenek. Tisztában vannak az adatmodellezés statisztikai, matematikai alapjaival is, de amint az üzleti alkalmazhatóság a kérdés, már nehézségekbe ütköznek. Nehezen tudják kommunikálni a megrendelő felé az eredményeket, mert általában nem egy nyelvet beszélnek a döntéshozókkal.
Hasonlóan az informatikusok is a modellezéssel vannak jobb kapcsolatban, automatizálni tudnak egy-két folyamatot, de erős statisztikai háttér hiányában az adatok előkészítése már nehezebb feladat számukra. Az, hogy milyen új változókat érdemes létrehozni, vagy az elkészült modell az elvárásoknak megfelel, vagy üzletileg használható-e, már kiesik a figyelmük köréből.
Szociológusokkal is találkozni az adatbányászok között, nekik az előnyük szintén statisztikai tudásukból ered, klaszterezés esetén a csoportok leírása is könnyebben megy nekik, és talán a modellezésre érdemes változók körét is jobban meg tudják határozni.
És hogy hol lehet konkrétan adatbányászatot tanulni?
Próbáltam utánanézni, hol is tanítanak adatbányászatot a nagy egyetemeken kívül, de arra jutottam, hogy még a NYME- Faipari Mérnöki Karának egyik szakán is kiemelt téma az adatbányászat, és úgy tűnik minden egyetemen és főiskolán megtalálható legalább hasonló szak vagy legalább pár tárgy (adatbányászat, adatelemzés, üzleti döntéshozás támogatása, vagy adatmodellezés). Így a fő kérdés az, hogy milyen egyéb terület érdekel, hogy milyen iparágon belül szeretnél adatbányászattal foglalkozni.
Az adatbányászok munkájának nagyon fontos pontja az adatok megjelenítése, több szempontból is oda kell figyelnünk erre. Egyrészt már az egyes változók értékeinek, eloszlásainak vizuális vizsgálata is rávilágíthat összefüggésekre, segíthet a változók kiválogatásában, új változók generálásának szintén az alapja lehet; másrészt az eredményeket a megrendelő számára is emészthető formában kell tálalni. Általában minél kevesebb, minél informatívabb adatot érdemes kiemelni, és az sem mindegy, hogy milyen formában: könnyen érthetőnek kell lennie és meg kell ragadnia a figyelmet. (Ezzel kapcsolatban érdemes elolvasni Kővári Attila blogján található írást.)
Az adatvizualizáció nagyon fontos szerepet játszik tehát az elemzők életében, de sajnos kevés olyan adatbányászati szoftvert találni, amelyben megfelelő, jól paraméterezhető, “adatra szabható” és egyben esztétikailag is elfogadható grafikonokat készíthetnénk. A legelterjedtebbek még ma is az Excelben készült egyen-diagrammok. Egyszerűsége és elterjedtsége szerintem még sokáig vezető pozícióban tartja a vizualizáció terén. Klasszikus értelemben vett adatbányászati eszközök közül a leghasznosabb és esztétikusabb adatmegjelenítő eszköze talán a SAS Enterprise Minernek van, valószínűleg nem véletlenül ez a legdrágább adatbányászati szoftver...
Ha tehát nincs végtelen költségvetésünk, de az Excelnél kreatívabban szeretnénk megmutatni az adatokat, speciális grafikai eszközhöz kell nyúlnunk, vagy ha még ennél is komolyabban vesszük, akár egy designer segítségét is igénybe lehet venni.
Ha már a design-nál tartunk, egyre elterjedtebbek az infografikák, amik személy szerint nagyon megnyerték a tetszésemet, mert hihetetlenül kreatív módon, az adat jellegéhez kapcsolódva jelenítik meg azokat, így segítve a megértést. Biztos vagyok abban is, hogy ilyen módon jobban el tudjuk tárolni az információkat az agyunkban, mert a képek segítik a rögzítést. Az üzleti intelligencia világában az infografikákat a modern vezetői riportokkal (dashboardok) hozhatjuk párhuzamba, amelyeket szintén úgy fejlesztenek, hogy kevés információt hatékonyan jelenítsenek meg, kiemelve a lényeget.
Érdemes megnézni a youtube-on található videót, amin jól érezni, hogy mennyire kiegészítik egymást a nyers adatok és a képi világ.
Így karácsony közeledtével egy könnyedebb, de mégis elemzésről szóló témát találtam, a humor és művészet témakörét. Most nem a viccek vagy épp művészeti alkotások gépi elemzéséről lesz szó, hanem elemzői témájú viccekről, versekről. Náhány linket gyűjtöttem ezekről össze:
A Modern Analyst oldalon hetente több humoros kép is megjelenik, amely üzleti elemzőkről szól, számomra kicsit fura a humora, de lehet benne kivételeket találni, ez például személyes kedvenc.
A kdnuggets.com-ot látogató adatbányászok meglehetősen kreatívak, ez magyarázhatja azokat a gyöngyszemeket, amiket az oldalukon találtam. 2005-ben hirdettek versenyt adatbányászati témájú haiku írására, nem tudtam eldönteni, melyik a legjobb, így várom a szavazatokat, vagy a ti beadásaitokat.
Ezen kívül volt limerick-író versenyük is, ezen is briliáns eredmények születtek, érdemes elolvasgatni.
Ezekkel kívánok minden olvasómnak kellemes Karácsonyt, boldog új évet és jó pihenést!
A versennyel még nem sikerült haladnom, így arról még kevés újdonsággal tudnék szolgálni, viszont van egy téma, amit eddig elkerültünk, de érdemes vele foglalkozni. Ez pedig a modellek témája. Eddig átléptem a problémát azzal, hogy ha megvan az adat és a célváltozó, építünk rá egy modellt; most nézzünk a mélyére: milyen modellekkel dolgozunk leggyakrabban?
Személy szerint amióta adatbányászom, két modell-típussal volt főként dolgom: döntési fákkal és regresszióval. Ennek több oka is van: ezek régen bevált, egyszerűen magyarázható eljárások, azaz a modell eredménye könnyen átadható az üzlet részére. Megfigyelésem szerint a tanácsadó szektor (amiben én is tevékenykedem) legnagyobbrészt ilyen modellekkel dolgozik. Saját vagy ennél bonyolultabb algoritmusokat újszerű problémákra vagy specifikus területen alkalmaznak, és vagy a cég saját adatbányászai programozzák le, vagy az egyetemi szférából kerül ki a fejlesztő.
De nézzük is a két fent említett modellt:
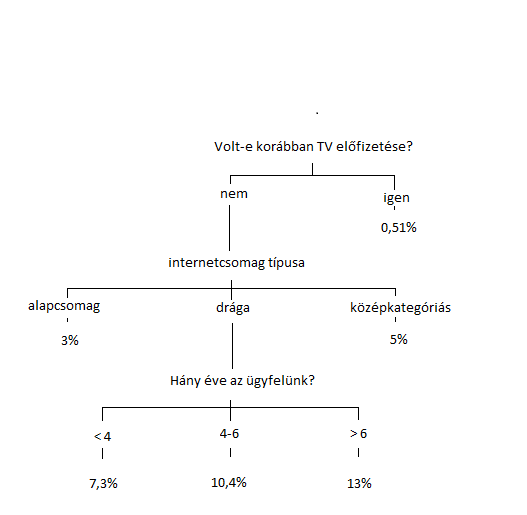
A döntési fa a legegyszerűbb és ennek ellenére nagyon hatékony modelltípus. A lényege, hogy az adatbázist darabolni kezdi az egyes lépésekben egy-egy változó értékeitől függően. Olyan mutatók mentén, mint pl. az entrópia (információ-nyereség), kiválasztja, hogy melyik változó különböző értékei mellett lehet úgy darabolni az adatbázist, hogy a részekben a legnagyobb legyen a különbség az esemény-arányok között. Egy egyszerű példa a döntési fára: az alábbi fa egy hipotetikus modellje annak a döntésnek, hogy ki fog venni legvalószínűbben új TV csomagot. Összesen három változó felhasználásával az ügyfeleket 6 részre osztja, és minden csoportban (levelek) megmondja, hogy mennyi a vásárlók aránya. Ez nagyon szemléletes és viszonylag egyszerű modell, két dologra is alkalmas: Egyrészt az ügyfeleket sorrendezni lehet az alapján, hogy melyik csoportba kerülnek, és azoknak ajánlani a TVcsomagot, akik valószínűbben megveszik, másrészt a változók megvizsgálása után levonható arra vonatkozóan következtetés, hogy hogyan érdemes változtatni az üzletmeneten. Ebből a fiktív példából kiindulva például dönthetünk úgy, hogy felülvizsgáljuk a terméket, mivel akinek egyszer már volt ilyen, azok elhanyagolhatóan kis arányban vesznek újra, tehát valószínűleg nagyon elégedetlenek.
A regressziós modell ennyire nem szemléletes, minden egyes bemeneti változóra megmondja, hogy értéke milyen mértékű változást okoz a célváltozó értékében. Nézzünk egy másik példát, mondjuk, hogy egy lakás árát jósoljuk meg a jellemzői alapján. Egy regressziós modell minden egyes numerikus változóhoz képez egy szorzót, majd az egyes szorzatokat összeadva kijön az lakás jósolt értéke, pl:
ár = hány négyzetméter a lakás * x1 + lakás állapota (0-100-as skálán) * x2
Az ár kiszámításán kívül a modellből látszik, hogy az egyes tényezők hogyan befolyásolják a végső árat: ha egy együttható negatív, akkor a jellemző növekedése csökkenti az árat, ha 0-hoz nagyon közeli, akkor annak kis változása kevéssé befolyásolja azt.
Ezek a modellek hát azok, amiket leggyakrabban használunk, minden komolyabb adatbányászati szoftverben ezen modelleknek több fajtája is megtalálható beépítve.
Adatbányászati szoftverek
Címkék: oracle clementine rapidminer adatbányászati szoftver
2011.12.01. 11:21
Az egyetemen több adatbányászati eszközzel is volt lehetőségem megismerkedni, ezekből fogok szemezgetni, megemlítve a drága, fizetős eszközöket is, de főleg arra koncentrálva, hogy mivel érdemes egy kezdő/hobbi adatbányásznak kezdenie.
Milyen követelményeket támaszthatunk egy adatbányászati szoftverrel? Szerintem amit egy szoftvernek tudnia kell, hogy önállóan adatbányászati eszköznek nevezhessük:
- több adatbázistípusból tudjon olvasni adatot
- lehessen az adatokat manipulálni, átalakítani, “szerkeszteni”
- lehessen vele műveleteket végezni az adatokon, új változókat létrehozni
- különböző adatmegjelenítők megléte sem hátrány, tehát az adatokat legyen lehetőségem grafikonokat is létrehozni
- tartalmazzon több modelltípust, amivel az adatokból az összefüggéseket ki lehet nyerni
Nagy vonalakban ennyit kell tudnia egy eszköznek, ez az, amivel már lehet hobbi illetve munka szinten is adatbányászni.
Ezeket a követelményeket több szoftver is teljesíti, három nagy cégnek van komplett megoldása ilyen feladatokra:
A fizetős szoftverek közül leginkább az IBM Modelert ismerem és tudom ajánlani: az IBM egy pár évvel ezelőtt az SPSS felvásárlásával szert tett az SPSS Clementine szoftverre (ebből lett az IBM Modeler), amit egyszerű, grafikus felületének köszönhetően nagyon könnyű használni.
A SAS rendelkezik még komoly eszközzel, ami még drágább az előzőnél, és még összetettebb, ezért elsajátítani sem olyan egyszerű a használatát, de sok jó funkcióval rendelkezik, például sokkal erősebb és okosabb grafikonokat tud létrehozni.
A harmadik versenyző az adatbázisairól híres Oracle, akinek Data Miner nevű szoftverével akár adatbányászni is lehetne, de nem ajánlott. Egyszerű kezelhetősége mellette szól, amikor utoljára dolgoztam vele, a Microsoft termékeihez hasonlóan varázsló segítségével össze lehetett benne rakni adatbányászati projekteket, de kissé körülményesnek tűnt a meglévő lépéseken változtatni, és úgy általában adatmanipulálni vele.
Ennyit a nagy és drága szoftverekről.
A válság hatására az adatbányászok is elkezdtek ingyenes mégis mindenttudó megoldásokat keresni, ennek köszönhetően egyre nagyobb tért hódít az üzleti életben is a Rapid Miner nevű szoftver. Ingyenes, mindent tud a felsoroltak közül, és aki nem tud megvenni egy drága szoftvert, az remekül kiválthatja azokat ezzel. Az egyetemi szférából indult, Németországból, és a gyors fejlesztéseknek köszönhetően ma már ez is egyszerűen elsajátítható, grafikus kezelőfelületű programmá vált. Kezdők számára csábító lehet, hogy nagyon jó help, tutorial van hozzá, és sok oktatóvideó található a youtube-on is, ha pedig kérdésed van, egy egész community áll mögötte, akik válaszolni tudnak. Előnye még, hogy ha programozói vénával rendelkezel, hogy saját építőkockákat fejleszthetsz bele, illetve építhetsz rá saját alkalmazásokat, mivel ez egy open-source szoftver. Ennek köszönhetően sok kiegészítő is található már hozzá, és még több várható a közeljövőben, mivel már béta verzióban van a Rapid Miner Marketplace, ahol egyelőre ingyenes kiegészítőket lehet letölteni, később fizetős verziók megjelentetésére is számítani lehet. A szoftver hátrányait is meg kell említeni: ezek főképp akkor jelentkeznek, ha nagyobb adatbázisokkal kezdesz dolgozni és gyenge géped van hozzá, mert szereti megenni a memóriádat. (2GB memóriával még a százezernél kevesebb rekordszámú adatbázisokat sem feltétlenül tudja kezelni.) Másik negatívuma nem konkrét hibához kapcsolódik, de többször is tapasztaltam már, hogy nem minden művelet úgy működik benne, mint azt a felhasználó elvárná, néha meglepő hibákat tud generálni. De ezen túl lehet lépni ha azt nézzük, igazából rendelkezünk egy adatbányászati szoftverrel, ingyen, ennek az ár-érték aránya tehát magasan a legjobb, ha az árnak pl. a kezelés elsajátításának idejét vesszük.
Nektek mi a véleményetek a felsorolt/fel nem sorolt adatbányászati szoftverekről?
Az első posztban szó esett adatbányászati versenyekről, de nem említettem többször ezt a témát, pedig érdemes neki posztot szentelni. Az egyik legfelkapottabb startup mostanában a Kaggle csapata. A kaggle.com adatbányászati versenyek szervezésével foglalkozik. Maga az üzleti modell is érdekes, a megrendelő biztosítja a feladatkiírást, az adatbázisokat, a kaggle honlapján regisztrált (akár hobbi-) adatbányászok pedig csatlakozhatnak a versenyekhez és beküldhetik az általuk kapott eredményeket, amelyek kiértékelésre kerülnek.
Egy versenyfeladatról írnék most, bár a verseny még nem fejeződött be, és egyelőre eredményesnek sem mondanám magam a mezőnyben, mégis alkalmas arra, hogy mélyebben belemenjek, milyen általában egy adatbányászati projekt.
A verseny a “Don’t Get Kicked” elnevezést kapta, a célja, hogy aukciókon értékesített autókról hogyan lehet biztosabban eldönteni, hogy rossz vétel. Az autókereskedők néha aukciókon vásárolnak autókat, amik között előfordul, hogy később nem tudják valami hibája miatt eladni (rejtett hiba, visszapörgetett km-óra, stb.) A rendelkezésre álló változók az autó jellemzői (márka, modell, kor, futásteljesítmény, felszereltségi osztály...) és az aukció jellemzői, azaz hogy ki vette meg, melyik aukciós ház értékesítette, mennyiért, mikor, online aukció volt-e... Ezen kívül olyan árak állnak még rendelkezésre, hogy hivatalosan aukción vagy a kereskedésben mennyire becsülik hivatalos szakértők az autó árát.
Ahhoz, hogy a teszt-adatbázisban lévő autókra meg tudjuk mondani, hogy mekkora valószínűséggel nem lehet majd tovább-értékesíteni hiba miatt (rossz vétel), érdemes az adatokat transzformálni, új változókat bevezetni.
Ahhoz például, hogy megállapítsuk, hogy a km-óra manipulálták-e, érdemes kiszámolni az átlagos futtott km-t évente. A feltűnően alacsony értékek nagyobb valószínűséggel babráltak. Ha ezt nem tartjuk elegendőnek, akkor azt is megnézhetjük, hogy kategóriájában alacsonynak vagy magasnak számít-e az adott futásteljesítmény (kis autókba jellemzően kevesebb km-t tesznek évente).
Ilyen és ehhez hasonló előfeltevések alapján készíthetünk új változókat, amik növelhetik a modell-teljesítményt.
Az adattranszformációra egy példa a rosszul feltöltött értékek cseréje (a mező tartalmazza ugyanazt az értéket kis és nagybetűsen is); vagy a hiányzó értékek feltöltése. Ez utóbbinak egy érdekes megvalósítása, ha már a hiányzó értéket is egy modell segítségével határozzuk meg. Az említett autós adatbázisban sok helyen hiányos az árbecslés, így ezt a rendelkezésre álló változók alapján egy modell segítségével akár mi is megbecsülhetjük. Az első modelljeimet ilyen feltevések mellett építettem, mint írtam, jó eredményről nem tudok még beszámolni (középmezőnyből csúszok lefelé), de ha lesz szabadidőm, akkor kísérletezek kicsit a modellekkel, és megírom, mire jutottam. :)
A következő posztban még lesz szó arról, milyen eszközöket lehet használni hobbi-adatbányászként a feladat megoldására, és milyen egyéb feladatok lehetnek még az adatokkal.
Adatbányászok a bankokban II. - A hálózatok világa
Címkék: bank válság gráf adatbányászat hálózatkutatás barabási albert lászló bedőlés
2011.11.15. 12:18
A pénzintézetekben való adatbányászatról már volt szó, most ezt egészíteném ki egy érdekes, adatbányászattal megoldható feladattal.
A banki és egyéb szektorban is kiemelt figyelmet fordítanak a vállalati ügyfelekre, mivel nagy és nagy bevételeket lehet belőlük generálni. A gazdasági válság során egyre több cég szűnik meg azonban, ami nagy bevétel-kiesést jelent a bankoknak, így tudni szeretnék, hogy mely cégeknél lesz várhatóan csőd. A cégek bedőlése (megszűnése/csődbe menés) az esetek többségében azért történik, mert a beszállítói, vagy azok akiknek szolgáltat, fizetésképtelenné válnak.
Hogyan veheti észre a bank, hogy egy ügyfele várhatóan csődöt jelent? A manapság egyre elterjedtebben használt hálózat-elemzés lehet a segítségére. Ezzel ugyanis lehetősége nyílik arra, hogy az átutalásokból hálózatot (gráfot) építsen, és megfigyelje, hogy egy-egy cég bedőlése hogyan befolyásolja a környezetében lévő cégeket. A gráf csomópontjai a cégek, az élek köztük az átutalások, és az élekhez egy súlyt is lehet rendelni, ez másképpen a fertőzési index, azaz azt mutatja meg, hogy mennyire valószínű, hogy az adott élen “terjed a bedőlésveszély”, azaz az egyik cég bukása mekkora mértékben befolyásolja a másik cég bukását is. Józan ésszel gondolkodva ez biztosan arányos az átutalt pénz mennyiségével, de más dolgok is befolyásolhatják az értékét, pl. hogy hány másik céggel van kapcsolata még, stb.
Az ilyen hálózati elemzéseket már említettem a telefonos adatok adatbányászatánál is, ahol szintén a felhasználó környezetének felderítése volt a cél, csak ott az információ (új díjcsomag) terjedése volt a kérdéses, nem a bedőlésé. Az ilyen és ehhez hasonló hálózatok tanulmányozása már régóta tart, hazánkban is több jeles kutató foglalkozik vele: Csermely Péter, Vicsek Tamás és Barabási Albert-László, aki két könyvet is írt a nagyközönség számára Behálózva és Villanások címmel, amit érdemes elolvasni.
Mi mást tud rólad még a telefonod?
Címkék: telefon hálózat szolgáltató telekommunikáció adatbányászat uplift hívásszokás
2011.11.07. 19:07
A már említett telefonos adatbányászati modelleket minden nagy szolgáltató használja, de ezen kívül még lehetnek adatbányászattal megoldható, ennél érdekesebb feladatai is. Az alábbiakban ezekből szemezgetünk:
- Az ügyfelek hívás-adatai alapján tud építeni egy hálózatot az egymást hívogató ügyfelekből, és ebből azonosítja az ügyfél ismerősi körét. A hálózat alakjából megmondható például, hogy milyen szerepet töltessz be az adott ismerősi körben: a központi alak vagy, aki mindenkivel kapcsolatban van, vagy a hálózat “szélén” helyezkedsz el, aki nem sok emberre van befolyással. A már régóta folyó kutatások azt mutatták ki, hogy ha egy terméket el szeretnének terjeszteni, érdemes a központi emberek melletti ügyfeleknek eladni, az ő ismerősi körében így terjed el legjobban a termék.
- Jellemző a telekommunikációs szolgáltatókra (és a bankokra is), hogy az új ügyfeleknek jobb kondíciókkal ajánlanak terméket, mint a már meglévőknek. Ennek megfelelően megjelentek azok az ügyfelek, akik lemondják a szolgáltatást, majd új ügyfélként jelentkeznek újra ugyanannál a szolgáltatónál. Már több módszer is van arra, hogy ezeket az ügyfeleket azonosítani tudják az adataikból. Az egyik módszer szintén a hálón alapuló modell, amikor megnézik, mennyire hasonló egy régebbi ügyfélhez azok köre, akiket fel szokott volt hívni a régi ügyfél. A másik módszer is a hívásszokásokon alapul, de az azt vizsgálja, hogy a hívások időtartama, jellemző időpontja (vagy napszak) és összege mennyire egyezik. Ezen kívül még lehet figyelni azt is, hogy jellemzően honnan telefonál az ügyfél (az ún. cella-információk alapján nagyjából lehet azonosítani a hívásindítások helyét). Ha két ügyfél (egy múltbeli, és egy jelenlegi) azonos körzetekből telefonál, azonos időpontokban, nagy valószínűséggel megegyezik a két ügyfél.
- Egy előző posztban említettem, hogy a szolgáltatók üzemeltetnek olyan modelleket, amelyek megmondják, melyik termék érdekelhet a legjobban, ezt kétféleképp használhatják fel: ha te keresed meg az ügyfélszolgálatot, akkor az ügyintézés során mellékesen megkérdik, nem érdekel-e az adott termékük. Másrészt fel is hívhatnak egy kampány keretében, hogy nem vennél-e meg valamit. A szolgáltatók felismerték, hogy ebben a második esetben az ügyfelek reakciója eltérő lehet: Van aki azért fog utánanézni, létezik-e más szolgáltatónál jobb ajánlat számára, mert felhívták rá a figyelmét, hogy a jelenlegi díjcsomagjánál lehet kedvezőbbet találni a saját szolgáltatójánál. Van, akit hiába hívnak fel bármilyen ajánlattal, nem fog reagálni rá, és van olyan is, aki meggyőzhető egy jó ajánlattal, és hűséges a szolgáltatóhoz. A negyedik csoport pedig az, aki a hívás nélkül is megvette volna a terméket, tehát a kampány költsége megtakarítható lett volna. A kampányra adott ügyfél-reakciók alapján tehát négy csoport állítható fel egy modell segítségével, ami azt méri, hogy kampány nélkül és kampányolással mennyire valószínű az ügyfél vásárlása (uplift modell).
A pénzintézetek az egyik legnagyobb megrendelői az adatbányászati elemzéseknek, elterjedten használják a modelleket a működésük támogatására. Az oka, hogy ebben a szektorban közismerten sok a pénz (mily meglepő) és nagy a kockázat, így a kockázat csökkentése érdekében több eszközt is bevetnek. Ezen kívül a bankok is hasonlóan nagy adatbázissal rendelkeznek az ügyfelekről, mint a telekommunikációs szolgáltatók. Demográfiai adatokon kívül rálátnak az ügyfél náluk vezetett számlájának teljes forgalmára és összetételére, rögzítik a telefonos megkereséseket, és a hívások okát. Pénzügyi intézmények több célra is felhasználják az adatokat: például az ügyfelek megtartására, vagy a kockázatok csökkentésére a hitelezés során.
Az adataik segítségével a bankok előre tudják jelezni, hogy az ügyfél lezárja a bankszámláját, azaz bankot szeretne váltani (churn modellek): ha az adatok alapján épített modell szerint nagy a valószínűsége, hogy otthagyja a bankot, akkor fel lehet hívni őt egy jobb ajánlattal, kedvezőbb befektetési lehetőséggel, ami maradásra bírhatja. Az adatbányászati algoritmusnak itt is az a feladata, hogy megmondja, melyik viselkedéssel kapcsolatos változók jelzik előre, hogy az ügyfél az összes pénzét “kimenekíti” a bankból, és felmondja a szerződését. Az adatokban például az utalhat erre, ha elkezdi átutalgatni a pénzét vagy csökken a szokásos forgalma a bankszámlán.
A hitelek-elbírálása során modell jelzi előre az ügyfél “megbízhatóságát”, ami megmondja, mennyire lesz jó adós az adott hitelkérelmező. Ezt figyelembe veszik a hitelbírálat folyamán, ha nem is csak ez alapján döntenek. Ez a vagyoni helyzeten, pénzmozgáson alapul, ezen kívül aki vett már fel hitelt, tudja mennyi papírt kell leadni, ezeket mind felhasználják a modell megalkotására.
Mindkét esetben (bankváltás, illetve hitelezés) rendelkezik múltbeli tapasztalattal a bank azzal kapcsolatban, kik zárták le számlájukat, illetve kik voltak rossz adósai, ezek alapján próbálja meg előrejelezni a valószínűségét annak, hogyan fognak viselkedni a még meglévő/új ügyfelei.
Ennyit elsőre a bankokról, folyt. köv :).
Te is célpont vagy! - Hírek reklámért
Címkék: reklám hír hírportál adatbányászat célzott hirdetés targetált hirdetés
2011.10.26. 13:31
Az előző posztban már előkerültek a hírportálok, most egy kicsit más aspektusból is foglalkozzunk velük. Gondolkodtál már azon, miért éri meg hírportált üzemeltetni? Kifizetni a rengeteg írót, szerkesztőt, irodát azért, hogy te mindig friss híreket olvashass? Az előző posztban már előkerült, hogy a hirdetésekből származik a hírportálok bevétele, ezek szervezése tehát létfontosságú számukra.
A hirdető számára úgy éri meg legjobban reklámoznia magát, ha nagyrészt a célközönségét éri el. Mi a köze ennek a híroldalakhoz és az adatbányászathoz?
A hírportálok üzemeltetőjének lehetősége van arra, hogy feltérképezze az olvasási szokásokat: megnézi, hogy milyen témájú, milyen kulcsszavakat tartalmazó híreket olvasol gyakrabban, melyeket kevésbé. Ezzel a tudással ajánlhat a hirdetőknek olyan hirdetési lehetőséget, hogy a hirdető megmondhatja, milyen témához kapcsolódik leginkább, ki reklám célközönsége, az üzemeltető pedig csak azon olvasóknak jeleníti meg az adott hirdetést, akiknek témábavágó az érdeklődési körük. A hirdető annyit fizet, ahányszor megjelenik a reklám, és annyi bevétele lesz ebből, amennyien a reklám hatására veszik meg a terméket. A célzott reklámmal a hirdető kevesebbet fizet, mintha egy mindenkinek megjelenő reklámért fizetne, ugyanakkor valószínűbb, hogy csak a tényleges érdeklődőket fogja megtalálni a reklámmal, ha jól határozta meg a célcsoportot.
Vegyünk például egy autóhirdetést: a hirdető egy új, családi modellt szeretne reklámozni, a célcsoportja a 30-40 év közötti férfiak, akik általában autókról szóló híreket olvasgatnak. Tegyük fel, hogy ők a legvalószínűbb vásárlói az új autótípusnak a hirdető szerint. Ezután a portál azonosítja azokat az olvasókat, akik ilyen témájú cikkeket olvastak az elmúlt pár hónapban és egyéb olvasási szokásuk alapján férfiak (pl. pénzügyi/üzleti és sporthíreket olvastak nagyrészt, és nem gyakran kattintottak szépségápolással, egészségüggyel kapcsolatos cikkekre). Nekik fogja megjeleníteni a reklámot.
(A nem meghatározására ez persze csak egy példa, ami nagyrészt előítéleteken alapul, de valószínűleg jobban belövi a célcsoport nemét, mint a véletlenen alapuló válogatás. Másrészt a hirdető érdeklődési körének az eltalálása fontosabb, mint a neme, egy azonos érdeklődési körrel rendelkező nő is dönthet a családban autóvásárlásról.)
Ki is próbálhatjuk, mely oldalak működnek így, ha egy ideig az adott híroldalon specifikus híreket olvasunk, hogy mennyire találnak meg minket az adott témához illő reklámok.
Aki utánaolvasna bővebben: “magyarul” leginkább a ‘targetált hirdetés’ vagy célzott hirdetés kifejezést használjuk erre a témára.
A webes vásárlás az a terület, ahol legközelebbről találkozhatsz az adatbányászattal és leginkább hasznát veszed személyesen is. Ha vásároltál már könyvet, vagy gyakran nézegetsz egyéb webáruházakat, feltűnhet, hogy mindegyiken működik valamilyen ajánlórendszer, ami az aktuálisan böngészett terméken kívül más hasonló vagy kapcsolódó termékeket ajánl neked. Az ajánlórendszer feladata, hogy a felhívja a figyelmed egy másik termékre, amire szükséged lehet. A végső cél hasonló, mint az áruházaknál a vásárlói kosár elemzésénél: minél többet költs. Ezt elősegítendő olyan terméket ajánl neked, amit nagyobb valószínűséggel veszel meg. Annyi előnye van a neten működő áruházaknak, hogy nem csak azt tudják eltárolni, mit vettél meg, hanem azt is, mi mást nézegettél még, mi érdekelt még a vásárolt árun kívül, tehát többet tud meg rólad, mint amire egy valódi áruháznak lehetősége van.
Mit csinál az adatbányász a gyűjtött adatokkal? Egy adatbázisban az oldalra látogatók összes böngészése és vásárlása fel van jegyezve, azaz, hogy mely termékeket/cikkeket nézték illetve vették meg. Ha Te ilyen webáruházba látogatsz és megnézel egy terméket, akkor a rendszer az adatbázisból előkeresi azt a pár másik felhasználót, aki szintén megnézte a terméket, azt feltételezve, hogy az azonos termékek után érdeklődők ízlése/érdeklődési köre azonos. Ezek után olyan terméket fog ajánlani neked, ami a hozzád hasonló vásárlóknál előfordult. Minél több terméket nézel meg, annál pontosabban tudja beazonosítani az ízlésedet.
Az egyik legnagyobb fejlődés az ajánlórendszerek életében egy adatbányászati versenynek volt köszönhető. Egy amerikai online DVD-kölcsönző, a Netflix egy nagy díjazású adatbányászati versenyt hirdetett pár éve, aminek keretében a saját ajánlórendszerét kellett továbbfejleszteni. A versenybe sok oktatási intézmény és cég is bekapcsolódott és nagy tapasztalatot szereztek ajánlórendszerek fejlesztésében, amit később webáruházak fejlesztésében kamatoztattak. Ha bővebben érdekel, a verseny oldalán találsz bővebb infót róla.
Nem csak termékekkel, cikkekre is létezik már ilyen ajánló, például a hvg.hu oldalon. Ebből is látszik, hogy a termékvásárláson kívül cél lehet még ezzel a módszerrel az olvasottság és így a hirdetési bevételek növelése is (hiszen az online hírportálok a hirdetésekből tartják fenn magukat, és a hirdetések értékesíthetősége az látogatottság függvénye).
Ahogy az elején is említettem, az adat formája sokféle lehet, amivel foglalkozunk. Nemcsak táblázatok, de kép, videó, vagy akár szöveg is. A szövegek elemzésével foglalkozó speciális területet szövegbányászatnak hívják. Azért érdekesebb terület, mert a gép nem tudja értelmezni a nyers szöveges információt, így az előfeldolgozás sokkal több feladattal jár.
Szövegbányászatot többmindenre is hasznáhatunk, az egyik elterjedt felhasználási terület a véleménybányászat, amikor egy-egy termékről való általános véleményre kíváncsi a termék gyártója vagy forgalmazója. Ennek megfelelően léteznek olyan szoftverek, amelyek a facebookon, twitteren egy adott termékre vonatkozó jelzőket keresik, hogy visszamérhessék a termék népszerűségét. Egy ilyen alkalmazásra példa a SAS szoftvere. Ma már elég sokan a közösségi oldalakon osztják meg véleményüket mindenről - például hogy épp most vettek egy Milka csokit, és mennyire jó/rossz volt - és ezt a gyártó felhasználhatja a termék fejlesztésére, kevesebbet kell költenie piackutatásra, mert ezzel házhoz jön a fogyasztók véleménye. :) (Ha részletesebben is olvasnál a témáról kezdő adatbányászként, vagy csak érdeklődőként, keress rá az opinion-mining vagy sentiment analysis szavakra.)
Egy másik érdekes felhasználási területe a spam-szűrés vagy levélszemét-szűrés. A spam-szűrő dolga, hogy a leveleinket két csoportra ossza, a hasznos levelekre és a levélszemétre. Honnan tudja kiszűrni a szemetet? A spam leveleknek van pár közös tulajdonsága. Biztosan találkoztatok már olyan levéllel, aminek a fejlécéből már kiszúrtátok, hogy csak szemét lehet: erre utalhat az ismeretlen feladó, idegen nyelv, jellemző szavak... Ezeket figyeli nagyrészt a spam-szűrő is, ami be van építve már a legtöbb levelezőprogramba. Ezek nagy része tanítható is működés közben, tehát ha tévesen spamnek sorol be bizonyos leveleket, akkor lehetőség van visszajelezni a szoftvernek, hogy nem spam az adott levél (vagy fordítva, spam-nek jelölni azt, amit nem észlelt spam-nek). Ez arra szolgál, hogy legközelebb az ilyen leveleket már megfelelően sorolja be, tehát egyedi igényekre szabható.
Egy harmadik felhasználási területről az indexen volt olvasható a nyár folyamán egy hír. A cikkben szereplő szövegbányászati projekt célja az volt, hogy a szóhasználatból kiszűrje, hány szerzője lehetett a bibliának. Mivel mindenki más szavakat használ előszeretettel, máshogyan rakja össze a mondatait, színesebb jelzőket használ... a szöveg ezen jellemvonásaiból meg lehet határozni a szerzők számát.
P.S.: Kommentekben várom a véleményeket a blogról, ha sok összegyűlik, posztolok vélemény-elemzést róla :)
Mindenki, akinek van telefonja (akár mobil, akár vezetékes), és így szolgáltatója, egészen biztosan kapott már hívást tőle, hogy van egy jobb ajánlata számára. Erről is legtöbbször mi, adatbányászok tehetünk :)
A hívások két okból születhetnek: Vagy el akarnak neked adni valamit, amire szerintük “vevő” vagy, vagy úgy gondolják, hamarosan szolgáltatót szeretnél váltani, ezért felajánlanak valami olcsóbb csomagot, kedvezményt, stb. Két kérdés merül fel ezzel kapcsolatban:
Honnan veszik, hogy kiket kell felhívni akik valószínűleg megveszik a terméket? Honnan találják ki, hogy épp szolgáltatóváltáson gondolkodsz?
Ha belegondolsz, a telefonszolgáltatód rengeteget tud rólad. A szerződésben megadott alapadatokon kívül (demográfiai adatok, mint név, nem, lakóhely) rendelkezik olyan infóval, hogy milyen más szolgáltatásokat veszel nála igénybe (a szolgáltatók némelyikénél több termék is van - TV, internet - de a telefonhoz is vannak kiegészítő szolgáltatások, opciók). Ezen kívül mivel technikai okokból rögzítik a hívás-adataidat (pl. számlázáshoz is), ezt is bele tudják venni az elemzésbe - pl. hány percet, milyen gyakran telefonálsz, mennyit költesz rá, jellemzően melyik napszakban telefonálsz, stb. Ezek a saját adatai a szolgáltatónak, de ehhez még vehet más forrásokból is adatot. Például a demográfiai adatok kiegészítéseként olyan adatbázisokat vesz pl. piackutató cégektől, ami a lakóhelyre jellemző változókat tartalmaz, például, hogy az adott területen mi az átlagos kereseti szint, fiatalok, vagy inkább idősek az emberek, és így tovább.
Mi az adatbányász dolga az adatokkal?
A telekommunikációs cég átadja az adatokat az adatbányásznak (ez szolgáltatótól függően százezres-milliós nagyságrendű felhasználó adatait jelenti), és az a kérése, hogy adott termékére kik a legvalószínűbb vásárlók. Abból indulunk ki, hogy egy bizonyos csoport körében terjed inkább az adott termék, így az adatok alapján egy algoritmus megkeresi, mi a közös azokban az ügyfelekben, akik nemrég vették az adott terméket. Mivel a telefonos megkeresések a szolgáltatónak is pénzbe kerülnek, azzel a módszerrel tudja csökkenteni a költségét, ha csak azt a csoportot hívja fel, akik körében jobban kelendő a termék.
Nyergeljünk át a másik példára, a szolgáltatás-lemondásra. Honnan látszik, hogy egy ügyfél le szeretné mondani a szolgáltatását? Szerencsére mivel a szolgáltatónak már vannak olyan ügyfelei, akik lemondták a szolgáltatást, meg kell nézni, hogyan viselkedtek a szolgáltatás lemondása előtt, és ha azt látjuk, hogy most valamelyik még létező ügyfél ugyanígy viselkedik, akkor felhívhatjuk egy jobb ajánlattal, vagy küldhetünk neki SMS-t, hogy kapott 20 ingyen lebeszélhető percet. Mi lehet az a viselkedés, amire rálát a szolgáltató, és azt valószínűsíti, hogy szolgáltatót vált? Például hogy egyre kevesebbet telefonál, vagy többet reklamál a szolgáltatónál a termék miatt...
Ennyit tehát első körben a telefonos adatainkról, ezeket az alap-modelleket szinte minden szolgáltó használja, de ezen kívül még rengeteg dologra tudja felhasználni az adatokat, ezeket majd egy-egy posztban még részletezzük.
A következő néhány posztban pár olyan alkalmazási területet szeretnék bemutatni, ami szélesebb közösséget érint. Azt igyekszem leírni, hogy miért érdekes a cégek számára, hogy mit vásárolunk, mennyi telefonos forgalmat bonyolítunk, és milyen gyakran utalunk pénzt bankunkból.
Haladjunk egyesével, legyen az első talán a legegyszerűbb, a vásárlási szokásaink. A vásárlások elemzése az első területek között volt, ahol adatbányászati algoritmusokat használtak. Minden bevásárló-központban a kasszánál gépek rögzítik a vásárlásainkat, ezzel gyűjtenek információt a vásárlások összetételéről. Mire lehet azt az információt felhasználni, hogy mit vettem? Adatbányászati eljárásokkal azonosítani lehet a gyakran együtt vásárolt termékeket, és ezek elhelyezését tudják manipulálni az áruházon belül. Megfigyelték például, hogy a férfiak akik pelenkát vesznek, legtöbbször vesznek sört is. Ha ezeket az árukat az áruház két végében helyezik el, hogy a leghosszabb úton lehessen egyiktől a másikig eljutni, valószínűleg többet fognak vásárolni ezek a vevők.
Ezen kívül más reakciója is lehet az együtt vásárolt termékek azonosítása után a kereskedőnek, például hogy az egyik terméket akciózza, ugyanakkor a másik termék árát felviszi. Így az akciós termékért bemegyünk a boltba, de ha már ott vagyunk és meg szoktuk venni vele együtt a másikat is, gyakran nem is nézzük az árát. A reakciók meghatározása már nem mindig az adatbányász feladata, de gyakran mérhető egyik vagy másik reakció hatása (mennyivel többet fog költeni a vásárló), így a különböző lehetőségek közti választás egy optimalizálási feladat, amit szintén meg lehet oldani adatbányászati algoritmusokkal.
Mint említettem, ezeket a módszereket a kereskedők már régen ismerik és alkalmazzák, és napjainkra sokat fejlődött a technika, ami több lehetőséget ad a kezükbe. Gondoljunk csak arra, hogy régebben a visszatérő vásárlókat nem tudták azonosítani, így minden egyes vásárló kosara mintha új vásárlót jelentett volna. Ma már minden nagyobb láncnak van saját pontgyűjtő, vagy egyéb kártyája, ami nagyon is alkalmas arra, hogy a vásárlót azonosítsa. Ezzel lehetőség nyílik az egyes vásárlók egyedi igényeinek meghatározására, egyedi reklámokat, akciókat is lehetőség van bevezetni számukra.
Miért indítjuk a blogot? Szeretnénk bemutatni mindenkinek az adatbányászati szakmát. Ha hétköznapi környezetben elmondjuk, hogy adatbányászként dolgozunk, általában nehéz megmagyarázni, mit is jelent ez a gyakorlatban. Ha gyorsan túl akarunk lenni a válaszon, azt mondjuk, hogy adattáblákat nézegetünk egész nap. Ha kicsit jobban szeretnénk leírni a szakmánkat, belekapunk egy-két projektbe, amivel kapcsolatba kerültünk, de ez nehezen érthető és közel sem fed le mindent.
Pedig érdemes tudni mivel is foglalkozunk, mert a Te digitális lábnyomoddal is biztosan találkoztunk már! Hogy lehet ez? Jogos a kérdés: ügyfele vagy legalább egy banknak, van mobilod, szoktál vásárolni és még internetezel is. Ezekkel pedig rengeteg információt hagysz magad után, amivel gyakran ijesztgetnek, hogy ugyan mire is lehet felhasználni… Valóban sokmindenre, mi azt tudjuk bemutatni, hogy aki nem ártó szándékkal veszi kezébe az információt, mit tud belőle mondani Rólad, illetve az információt birtokló cég (a bankod, a mobil, vagy internetszolgáltatód, a bevásárlóközpont) mire kíváncsi ebből.
Blogunkkal ismeretterjesztő funkciót szeretnénk ellátni, mert hiszünk benne, hogy az adatbányászatnak nem kell mágikus szónak lennie, amiről a hétköznapi embernek – vagy Neked – valami titokzatos, sötét szakma jut eszébe. Mint például az adathalászat, ami hasonló ugyan, és sokan keverik, de valami egészen mást jelent.
Kezdjük is talán ezzel. Mi a különbség? Az adatbányászokat az információt teljesen legálisan birtokló cégek bízzák meg azzal, hogy nagy mennyiségű adataikból valami hasznos információt hozzanak ki. Ha a banki példánál maradunk: tegyük fel, hogy bankod minden nap kíváncsi rá, hogy mennyi volt az összes fiókjának az összes napi forgalma, és hogyan fog ez várhatóan alakulni az elkövetkező napokban. Az adathalász ezzel szemben nem legális módon (tipikusan jelszavakat megszerezve/feltörve) jut hozzá adatokhoz, hogy később visszaéljen vele – legyen ez e-mailcím vagy bankszámlaszám. A lényeg, hogy nem a saját legális adatbázisával dolgozik és visszaéléseket követ el. Ezek tehát nem mi vagyunk, mint látszik, teljesen más eszközök vannak a kezünkben és mások a céljaink is, mégis sokaknak közel áll a két fogalom egymáshoz. Bányászat és halászat tehát különbözik.
Most hogy körvonalaztuk mi az adatbányászat, ismerjük meg mélyebben is.
Nagy vonalakban mit is csinál egy adatbányász? Nagy adatbázisokból nyer ki a megrendelő számára hasznosítható információkat. Mindezt persze gépek segítségével, és legtöbbször nem első ránézésre egyértelmű információkat, hanem igénybe veszi a gép számítási erejét és az emberinél gyorsabb információfeldolgozási sebességét. Ez azt jelenti, hogy olyan programokat használunk, amelyek feldolgozzák az adatbázisokat és műveleteket tudnak végezni rajtuk, esetleg olyan intelligensek, hogy összefüggéseket is kinyernek belőle.
Egy dologról szól ezek után az adatbányász szakma: hogyan dolgozza föl az adatokat úgy, hogy abból használható információ legyen? Erről fog szólni a blog: milyen adatbázisokból, milyen kérdésekre keresik általában a cégek a választ, és milyen műveletekkel éri el azt az adatbányász, hogy hasznos választ tudjon adni a megbízó kéréseire.
Kezdjük mondjuk azzal milyen széleskörűen lehet alkalmazni az adatbányászatot.
Az adat alatt bármit érthetünk, bár előzőleg adattáblákat említettünk, az adat lehet képi információ, mozgókép, szöveg, egy honlap, de leggyakrabban adattábla, táblázat…
Hogy mennyire különböző területeken használnak adatbányászatot jól szemlélteti az egyik honlap, ami adatbányászati versenyek kiírásával foglalkozik. A következő három egy időben futó adatbányászati feladatot találhatjuk itt:
- Amerikai egészségügy beteg-adatai alapján (kor, nem, hányszor és milyen betegséggel volt ellátva) adjunk egy becslést arra, hogy a következő évben hány napot fog kórházban tölteni. Ez alapján az egészségügyi rendszer előre felkészíthető, megtehetik a szükséges fejlesztéseket, növelhetik/csökkenthetik az ágyszámot, stb. A cél nem mindig ismert, csak a feladat.
- Egy másik feladat űrteleszkópok képei alapján annak becslése, mennyire elliptikus egy-egy galaxis.
- A harmadik feladat annak a becslése, hogy egy-egy Wikipédia felhasználó aktivitása hogy fog alakulni a jövőben, hány lapot/hányszor fog szerkeszteni pár hónap múlva.
Mint látható, nagyon eltérő adatbázisfajták lehetnek a vizsgálat tárgyai, de a közös a feladatokban, hogy egy algoritmust várnak ezekre az adatokra alapozva ahhoz, hogy a kérdést megválaszoljuk. A fenti példák nem mindennaposak, nem gyakran előforduló feladatok. A gyakoribb feladatokról fogunk több szót ejteni, de néhány érdekes, ritkább projektről is szeretnénk azért szót ejteni majd.